A Primer on Joins

The golden rule of OLTP database design is that every table should represent one, and only one, entity-type. Without this rule, databases can exhibit three data anomalies (insertion, deletion, and update anomalies) that undermine data integrity. But adherence to the rule comes at a price of greater overhead (though it is a price well worth paying for data integrity). Data are spread out among more tables and so queries will have to do more work to bring together (or join) all the tables it needs (this overhead can be greatly reduced by running queries against an OLAP database instead, such as a data warehouse as we see in the data warehouse course 10777: Implementing a Data Warehouse with SQL Server 2012 SSIS).
So, what are joins, how do they work, and when do we use them? I’ll answer these questions with a few examples. If you want to follow along by doing, run the following script in your SQL Server Management Studio. It’ll create a database with two tables, SalesPerson and SalesOrder, related to each other by a foreign key in the SalesOrder table. When you are done with this article, you can issue a DROP DATABASE SalesRecords command and your server will be back to normal.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | USE master CREATE DATABASE SalesRecords USE SalesRecords CREATE TABLE SalesPerson (SPID int Identity(1,1) Primary Key ,SPName varchar(35) Not Null ,DeptID int NULL ,ContactID int NULL) CREATE TABLE SalesOrder (SOID int Identity(1,1) Primary Key ,OrderDate datetime Not Null ,ShipperID int NULL ,SPID int Not Null FOREIGN KEY REFERENCES SalesPerson(SPID)) INSERT INTO SalesPerson VALUES ('Marla Faulk', 5, 26), ('Chris Sheppard', 4, 53), ('Jess Weinstein', 5, 257), ('Haydee Dias', 5, 93), ('François Roubichaud', 2, 155) INSERT INTO SalesOrder VALUES ('5/4/2014 14:23', 3, 3), ('5/5/2014 10:38', 4, 2), ('5/5/2014 13:52', 3, 2), ('6/3/2014 09:13', 2, 2), ('6/5/2014 15:04', 2, 3), ('6/6/2014 13:01', 1, 1), ('6/8/2014 09:22', 3, 2) |
Feel the Need
Joins are necessary in queries that must use data from more than one entity-type. To see how this is, let’s have a look at our two tables.
1 2 | SELECT * FROM SalesPerson SELECT * FROM SalesOrder |
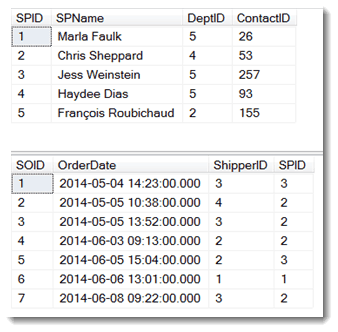
Let’s say we need an answer to this question: “What departments have used shipper 2 for their orders?” Department ids are in one table and shipper ids are in the other table. A query that answers this question will need to join the two tables.
How Does a Join Work?
A join is an operation of a query that brings together two table-type objects so that data in both can be used by the query.
A join has two inputs and one output. Inputs can be any table-type objects, including tables, views, table-valued functions, and other queries (though I’ll refer to the inputs of a join as tables in this article for simplicity). The two inputs must have a common column—usually a primary key/foreign key pair.
If we’re going to join the SalesPerson and SalesOrder tables, they’ll need to have a common column, and they do. The SPID in the SalesPerson table identifies a sales person and the SPID in the SalesOrder table does too—the sales person who placed the order. A value in one refers to the same thing that the same value in the other does.
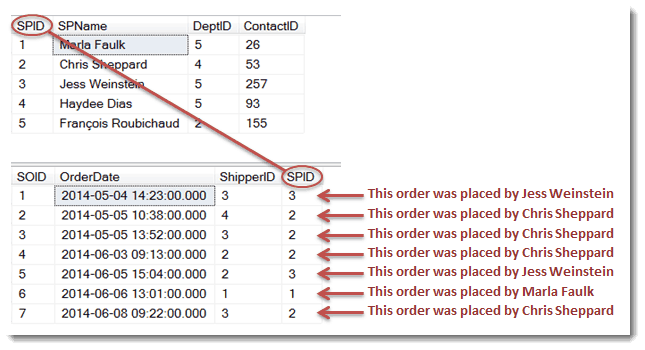
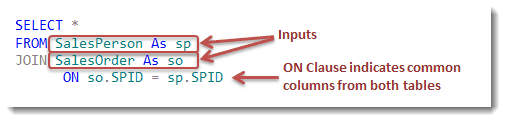
Here’s a query with a join that brings the two tables together on the common column, SPID (though our example uses two columns with the same name, common columns can have different names). This statement also creates aliases for the two tables, sp and so, that are then used throughout the query as needed.
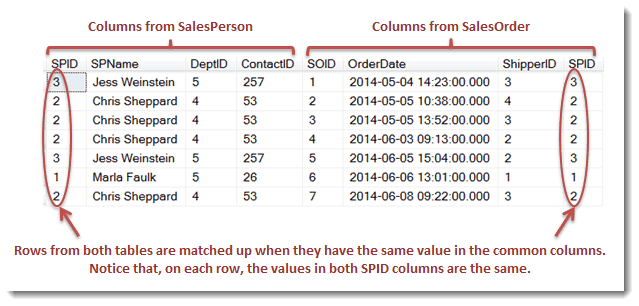
The join operation has a single output, which is a derived table consisting of all columns from both of the tables being joined but only matching rows from both of the tables. The join operation matches rows using the common column; rows from both tables with the same value in the common column are considered a match. Here is the derived table that is the output of the join above.
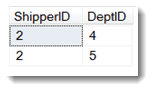
We can now select only the columns we want and refine the query so that we answer our original question about which departments used shipper 2. As you can see in the result of this next query, departments 4 and 5 both used shipper 2.
1 2 3 4 5 | SELECT DISTINCT ShipperID, DeptID FROM SalesPerson As sp JOIN SalesOrder As so ON so.SPID = sp.SPID WHERE ShipperID = 2 |
Types of Joins
Every join is either an inner join, an outer join, or a cross join.
Inner Join
An inner join eliminates rows from both inputs that don’t have matching rows in the other input. The example we just worked through is an inner join. Notice that SPID 4, Haydee Dias and 5, François Roubichaud, in the SalesPerson table have no sales orders (no matching rows in the SalesOrder table) and so they did not appear in the resulting derived table (the result of the query before the previous one). Those rows in the SalesPerson table were eliminated by the inner join.
Inner joins have a tendency of eliminating rows. Don’t be surprised if you see a reduction in rows when you use an inner join to add a table to your query!
By the way, the inner join can be written to include the optional world, INNER. The following query is identical to the one we wrote earlier without the word INNER:
1 2 3 4 | SELECT * FROM HumanResources.Employee As e INNER JOIN Person.Contact As c ON c.ContactID = e.ContactID |
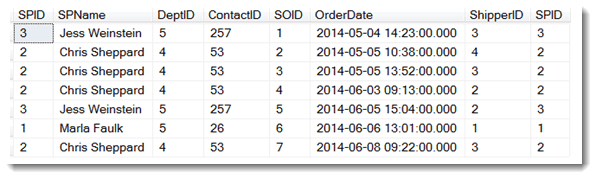
The result of an inner join between two tables is a derived table that includes all the columns from both tables and only the matching rows from both tables.
Outer Join
The outer join is similar to the inner join but it doesn’t eliminate rows from one or both tables; at least one of the tables is preserved. To specify which table(s) to preserve, use the words LEFT, RIGHT, or FULL in the join statement; the word OUTER is optional. If LEFT JOIN (or LEFT OUTER JOIN) is specified, then the table on the left side of the JOIN keyword will be preserved. If RIGHT JOIN (or RIGHT OUTER JOIN) is specified, then the table on the right side of the JOIN keyword will be preserved. If FULL JOIN (or FULL OUTER JOIN) is specified, then both tables will be preserved.
Let’s say the sales manager wants to find out which sales people do not have sales orders. In the following query, the SalesPerson table is preserved and the result now includes the two sales people with no orders—the ones with SPIDs 4 and 5 that were eliminated by the inner join we wrote earlier. Notice the NULLs in the columns of the table where there are no matches.
1 2 3 4 | SELECT * FROM SalesPerson As sp LEFT OUTER JOIN SalesOrder As so ON so.SPID = sp.SPID |
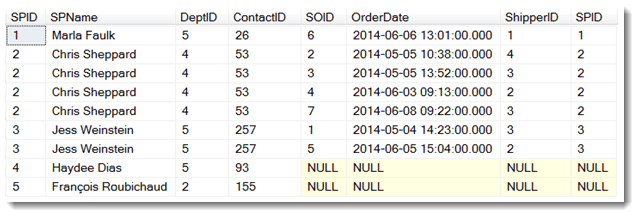
The left outer join preserves the table on the left side of the JOIN operation; all rows in that table are included in the derived table even if they don’t have matching rows in the table on the right side. If they don’t have matching rows, then NULLs are used.
Finally, to answer the sales manager’s question about which sales people do not have sales orders, we need only filter our outer join to show only those rows with a NULL in the primary key column of the SalesOrder table, since the only way that a primary key can have a NULL in it is if there is no match! We’ll also ask the query to display only the SPID and SPName columns.
1 2 3 4 5 6 | SELECT sp.SPID , sp.SPName SalesPerson FROM SalesPerson As sp LEFT OUTER JOIN SalesOrder As so ON so.SPID = sp.SPID WHERE SOID Is Null |
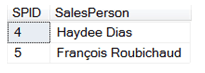
This type of exception question, “Which rows in this table have no matching rows in that table,” is a typical application for an outer join. Questions such as, “Which employees do not have resumes on file?”, “Which customers have not placed orders in the last six months?” and others can all be answered with outer joins.
But perhaps an even more common use for the outer join is when we need optional data. Optional data are data from another table that would be nice to have in a query but are not necessary to include if they don’t exist. In other words, if any rows in our query do not have matches in the new table, we don’t want that to be a reason to eliminate those rows that are already in our query. As an example, the previous outer join could have been used to fulfill the following request, too: “Show me all sales people and include their orders if they have any.”
Cross Join
The cross join is being mentioned here only for the sake of completeness. It is not a common join and should actually be avoided if possible, because it has a tendency to suck up resources. A cross join is a join that matches every row in one input to every row in the other input. For example, let’s say we want to match up every customer in the Customer table with every promotion in the Promotion table. The following cross join can accomplish that, assuming the two tables, Customer and Promotion, exist in the database:
1 2 3 | SELECT * FROM Customer CROSS JOIN Promotion |
I hope this article helps you get more from SQL.
Enjoy!
Peter Avila
SQL Server Instructor – Interface Technical Training
Phoenix, AZ




A Simple Introduction to Cisco CML2
Mark Jacob, Cisco Instructor, presents an introduction to Cisco Modeling Labs 2.0 or CML2.0, an upgrade to Cisco’s VIRL Personal Edition. Mark demonstrates Terminal Emulator access to console, as well as console access from within the CML2.0 product. Hello, I’m Mark Jacob, a Cisco Instructor and Network Instructor at Interface Technical Training. I’ve been using … Continue reading A Simple Introduction to Cisco CML2
Creating Dynamic DNS in Network Environments
This content is from our CompTIA Network + Video Certification Training Course. Start training today! In this video, CompTIA Network + instructor Rick Trader teaches how to create Dynamic DNS zones in Network Environments. Video Transcription: Now that we’ve installed DNS, we’ve created our DNS zones, the next step is now, how do we produce those … Continue reading Creating Dynamic DNS in Network Environments
Cable Testers and How to Use them in Network Environments
This content is from our CompTIA Network + Video Certification Training Course. Start training today! In this video, CompTIA Network + instructor Rick Trader demonstrates how to use cable testers in network environments. Let’s look at some tools that we can use to test our different cables in our environment. Cable Testers Properly Wired Connectivity … Continue reading Cable Testers and How to Use them in Network Environments